10.1 – Technische Entwicklungen
10.1.1 – Datenwachstum
Mengen von Daten wachsen typischerweise exponentiell. Berechnungen aus dem Jahr 2011 zufolge verdoppelt sich das weltweite erzeugte Datenvolumen alle 2 Jahre.[15] Diese Entwicklung wird vor allem getrieben durch die zunehmende maschinelle Erzeugung von Daten z. B. über Protokolle von Telekommunikationsverbindungen (Call Detail Record, CDR) und Webzugriffen (Logdateien), automatische Erfassungen von RFID-Lesern, Kameras, Mikrofonen und sonstigen Sensoren. Big Data fallen auch in der Finanzindustrie an (Finanztransaktionen, Börsendaten) sowie im Energiesektor (Verbrauchsdaten) und im Gesundheitswesen (Abrechnungsdaten der Krankenkassen). In der Wissenschaft fallen ebenfalls große Datenmengen an, z. B. in der Geologie, Genetik, Klimaforschung und Kernphysik.
10.1.2 – Big Data
Der aus dem englischen Sprachraum stammende Begriff Big Data (von englisch big ‚groß‘ und data ‚Daten‘, deutsch auch Massendaten) steht in engem Zusammenhang mit dem umfassenden Prozess der Datafizierung und bezeichnet Datenmengen, welche beispielsweise zu groß, zu komplex, zu schnelllebig oder zu schwach strukturiert sind, um sie mit manuellen und herkömmlichen Methoden der Datenverarbeitung auszuwerten.[1]
„Big Data“ wird häufig als Sammelbegriff für digitale Technologien verwendet, die in technischer Hinsicht für eine neue Ära digitaler Kommunikation und Verarbeitung und in sozialer Hinsicht für einen gesellschaftlichen Umbruch verantwortlich gemacht werden.[2] Dabei unterliegt der Begriff als Schlagwort einem kontinuierlichen Wandel; so wird damit ergänzend auch oft der Komplex der Technologien beschrieben, die zum Sammeln und Auswerten dieser Datenmengen verwendet werden.
10.1.3 – Cloud Computing
(deutsch Rechnerwolke oder Datenwolke[1]) beschreibt ein Modell, das bei Bedarf – meist über das Internet und geräteunabhängig – zeitnah und mit wenig Aufwand geteilte Computerressourcen als Dienstleistung, etwa in Form von Servern, Datenspeicher oder Applikationen, bereitstellt und nach Nutzung abrechnet. Angebot und Nutzung dieser Computerressourcen ist definiert und erfolgt in der Regel über eine Programmierschnittstelle (API) bzw. für Anwender über eine Website oder App.[2][3]
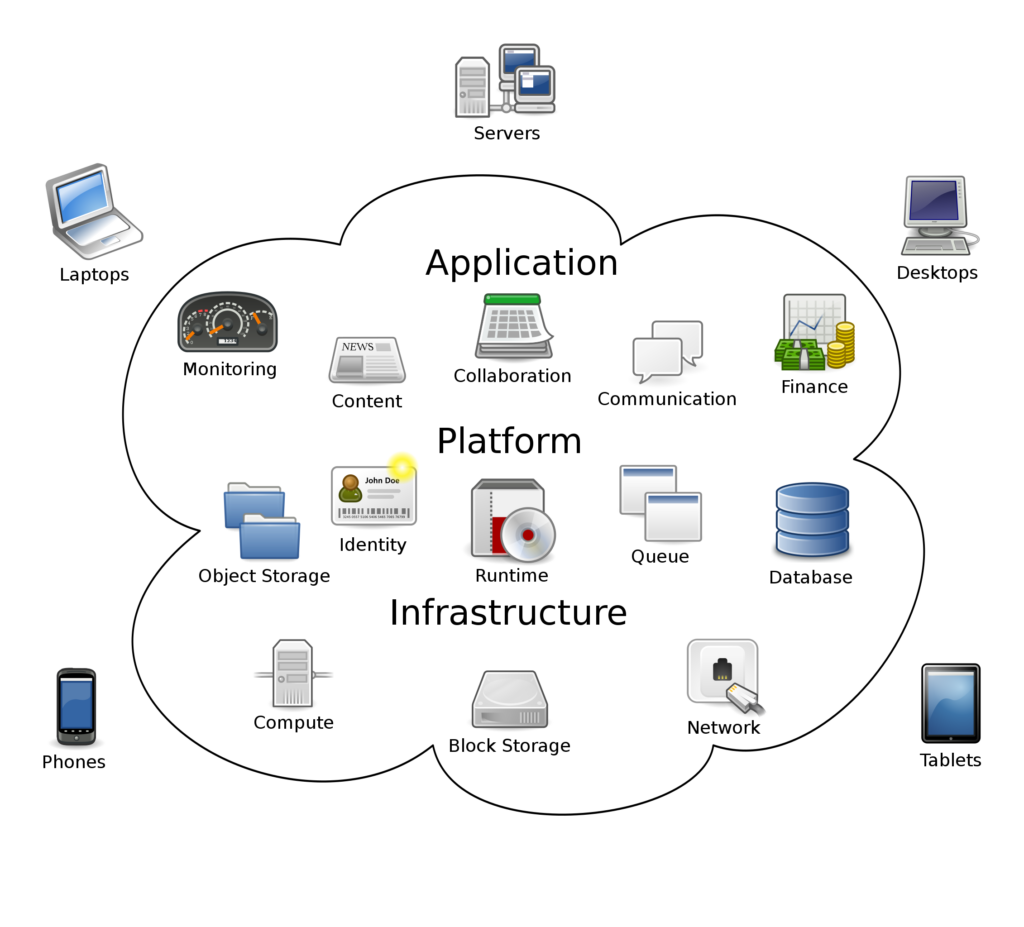
Abbildung 10.1 – Diagramm, das einen Überblick über das Cloud Computing mit den typischen Anwendungstypen zeigt, die von diesem Computing-Modell unterstützt werden.
10.1.4 – Physische Präsenz von Daten
Ein Rechenzentrum oder Datenzentrum ist ein Gebäude, ein bestimmter Bereich innerhalb eines Gebäudes oder eine Gruppe von Gebäuden, die zur Unterbringung von Computersystemen verwendet werden. Da der IT-Betrieb für die Geschäftskontinuität entscheidend ist, umfasst er im Allgemeinen redundante oder Backup-Komponenten und Infrastruktur für Stromversorgung, Datenkommunikationsverbindungen, Umgebungskontrollen und verschiedene Sicherheitsvorrichtungen. Ein großes Rechenzentrum ist ein industrieller Betrieb, der so viel Strom verbraucht wie eine Kleinstadt. Der Energieverbrauch ist ein zentrales Thema für Rechenzentren. Die Leistungsaufnahme reicht von wenigen Kilowatt für ein Serverrack in einem Schrank bis zu vielen Megawatt für große Einrichtungen. Einige Einrichtungen haben eine Leistungsdichte, die mehr als das 100-fache der eines typischen Bürogebäudes beträgt. Bei Einrichtungen mit höherer Leistungsdichte sind die Stromkosten eine dominierende Betriebsausgabe und machen über 10 % der Gesamtbetriebskosten eines Rechenzentrums aus.
Energieverbrauch Rechenzentren
Im Jahr 2020 verbrauchten Rechenzentren (ohne Kryptowährungs-Mining) und Datenübertragung jeweils etwa 1 % des weltweiten Stroms. Obwohl ein Teil dieses Stroms kohlenstoffarm war, forderte die IEA (International Energy Agency)) mehr „Anstrengungen von Regierung und Industrie in Bezug auf Energieeffizienz, Beschaffung erneuerbarer Energien und RD&D (Research, Development and Demonstration)“, da einige Rechenzentren immer noch Strom aus fossilen Brennstoffen nutzen. Es wird geschätzt, dass Rechenzentren im Jahr 2018 für 0,5 % der Treibhausgasemissionen in den USA verantwortlich waren.

Abbildung 10.2 – Innenaufnahme eines Datenzentrums
10.2 – Theoretische Grundlagen
10.2.1 – Daten
10.2.2 – Information

Abbildung 10.3 – Claude Elwood Shannon (1916 – 2001) war ein Amerikanischer Mathematiker, Elektroingenieur und Kryptograph, bekannt als ein “Vater der Informationstheorie”
10.2.3 – Wissen
10.2.4 – Daten, Information, Wissen, Weisheit
Die Wissenshierarchie (Informationshierarchie, Informationspyramide) bezieht sich lose auf eine Klasse von Modellen zur Darstellung von Strukturen und/oder Funktionen bzw. Beziehungen zwischen Daten, Informationen, Wissen und Weisheit. „Typischerweise wird Information in Form von Daten definiert, Wissen in Form von Information und Weisheit in Form von Wissen“.
10.2.5 – Data Mining
Unter Data-Mining (von englisch data mining, aus englisch data ‚Daten‘ und englisch mine ‚graben‘, ‚abbauen‘, ‚fördern‘)[1] versteht man die systematische Anwendung statistischer Methoden auf große Datenbestände (insbesondere „Big Data“ bzw. Massendaten) mit dem Ziel, neue Querverbindungen und Trends zu erkennen. Solche Datenbestände werden aufgrund ihrer Größe mittels computergestützter Methoden verarbeitet. In der Praxis wurde der Unterbegriff Data-Mining auf den gesamten Prozess der sogenannten „Knowledge Discovery in Databases“ (englisch für Wissensentdeckung in Datenbanken; KDD) übertragen, der auch Schritte wie die Vorverarbeitung und Auswertung beinhaltet, während Data-Mining im engeren Sinne nur den eigentlichen Verarbeitungsschritt des Prozesses bezeichnet.[2]
10.2.6 – Ontologie
Ontologien in der Informatik sind meist sprachlich gefasste und formal geordnete Darstellungen einer Menge von Begriffen und der zwischen ihnen bestehenden Beziehungen in einem bestimmten Gegenstandsbereich (in Anlehnung an den klassischen Begriff der Ontologie). Sie werden dazu genutzt, „Wissen“ in digitalisierter und formaler Form zwischen Anwendungsprogrammen und Diensten auszutauschen. Wissen umfasst dabei sowohl Allgemeinwissen als auch Wissen über sehr spezielle Themengebiete und Vorgänge.
Im Bauwesen existieren bereits mehrere Ontologien verschiedener Domänen und Fachrichtungen, die unter anderem durch die Linked Building Data Community Group und durch buildingSMART erarbeitet werden.
10.2.7 – Semantik
10.3 – Digitale Datenstrukturen
10.3.1 – Geographische Informations Systeme
Geoinformationssysteme, Geographische Informationssysteme (GIS) oder Räumliche Informationssysteme (RIS) sind Informationssysteme zur Erfassung, Bearbeitung, Organisation, Analyse und Präsentation räumlicher Daten. Geoinformationssysteme umfassen die dazu benötigte Hardware, Software, Daten und Anwendungen.
10.3.2 – Gebäude Informations Modelle
- Ein semantisches Datenmodell, das durchaus aus mehreren Modellen bestehen kann, die über ein Referenzmodell miteinander verknüpft sind.
- Der Modellierungsprozess, der sich über längere Zeiträume erstrecken kann und an dem Mitwirkende und Mitarbeiter aus vielen verschiedenen Bereichen beteiligt sind.
- Management des Modells: die Planung und Koordination von Daten- und Informationsflüssen.
10.3.3 – Industry Foundation Classes
10.4 – Digitale Prozessketten
Cloud Computing (deutsch Rechnerwolke oder Datenwolke) beschreibt ein Modell, das bei Bedarf – meist über das Internet und geräteunabhängig – zeitnah und mit wenig Aufwand geteilte Computerressourcen als Dienstleistung, etwa in Form von Servern, Datenspeicher oder Applikationen, bereitstellt und nach Nutzung abrechnet. Angebot und Nutzung dieser Computerressourcen ist definiert und erfolgt in der Regel über eine Programmierschnittstelle (API) bzw. für Anwender über eine Website oder App.
Die Ontologie (im 16. Jahrhundert als griechisch ὀντολογία ontología gebildet aus altgriechisch ὄν ón ‚seiend‘ bzw. altgriechisch τὸ ὄν ‚das Sein‘ und λόγος lógos ‚Lehre‘, also ‚Lehre vom Seienden‘ bzw. ‚Lehre des Seins‘) ist eine Disziplin der (theoretischen) Philosophie, die sich mit der Einteilung des Seienden und den Grundstrukturen der Wirklichkeit befasst, z. B. mit Begriffen wie Existenz, Sein, Werden und Realität.
Semantik (von altgriechisch σημαίνειν sēmaínein, deutsch ‚bezeichnen, ein Zeichen geben‘), auch Bedeutungslehre, nennt man die Theorie oder Wissenschaft von der Bedeutung der Zeichen. Zeichen können hierbei beliebige Symbole sein, insbesondere aber auch Sätze, Satzteile, Wörter oder Wortteile. Soweit sich die Semantik mit Zeichen aller Art befasst, ist sie ein Teilbereich der Semiotik. Sofern sie sich allein mit sprachlichen Zeichen befasst, ist sie eine Teildisziplin der Linguistik. Allgemeinsprachlich wird unter Semantik auch einfach die Bedeutung eines bestimmten Wortes, Satzes oder Textes verstanden.
Die Industry Foundation Classes sind ein offener Standard im Bauwesen zur digitalen Beschreibung von Gebäudemodellen.